



製造業エンジニアのためのCSVデータ分析入門|Python×pandasで集計&グラフ化
📂 Pythonの基本文法をまずは知りたい方は👇

💬 今日のテーマ:「CSVファイル、Excelで処理してませんか?」
製造業や研究開発の現場では、日々の測定データがCSV形式で出力されることが当たり前になっています。
たとえば──
- 硬さ、引張強度、耐久試験の結果
- 装置ごとのログ
- 検査結果やトレーサビリティ情報 など
こうしたデータは、見える化すること自体がゴールではありません。
📌 可視化とは、「現場の異常や傾向を捉える」ための“現状把握ツール”であり、
その先の品質管理・工程改善・機械学習モデル構築につなげるための第一ステップです。

しかし現場では、こんな課題もよく耳にします:
- 毎回CSVを開いて手作業でコピペ
- Excelでグラフ作成 → 書式調整で時間がかかる
- 条件別の比較や集計にひと苦労
🔧 Python(特にpandasライブラリ)を使えば、こうしたルーチン作業を効率化できます。
- CSVファイルを自動で読み込み、整形
- 欠損値や集計をワンライナーで処理
- seabornやmatplotlibでグラフも一発作成 → PNGで出力可能
製造業の現場で働くエンジニアにとって、
「今、現場で何が起きているか?」を素早く把握することは、日々の改善活動の起点になります。
本記事では、pandasを活用したCSVデータの読み込み〜集計〜可視化の基本ステップを、実務目線でやさしく解説します。
「Pythonって、こうやって使えるのかも」──そんな第一歩になれば嬉しいです。
📦 1. PythonでCSVファイルを読み込もう(pandas入門)
まずはお決まりのコードから:
🧪 ダミーデータ例(硬さ試験/製品別ロット情報)
import pandas as pd
data = {
"製品型番": ["AX100", "AX100", "BX200", "BX200", "CX300"],
"測定値_硬さ": [95.2, 97.5, 88.0, 90.1, None],
"ロット番号": [101, 101, 102, 102, 103],
"測定日": ["2024-03-01", "2024-03-01", "2024-03-02", "2024-03-02", "2024-03-03"]
}
df = pd.DataFrame(data)df = pd.read_csv("test_data.csv", encoding="shift-jis", skiprows=1)💬 現場エンジニアが実感するデータ活用の”あるある”
しかし、現場のCSVファイルは一筋縄ではいかないことが多いです。
- 1行目に「記録日時:」や「測定者名:」などのメタ情報が入っていて、表データが2行目から始まる
- 保存形式が
shift-JISになっており、UTF-8で読み込もうとすると文字化けやエラーが出る
こうした場合も、pandasならオプションで柔軟に対応可能です:
✅
encodingとskiprowsを指定すれば、日本語ファイルやメタ付きCSVでもスムーズに読み込みが可能です。💡 「エラーが出る → Excelで一度保存し直す」ような非効率な作業、もう不要です!
2. データの中身をざっくりチェック
まずは簡単なダミーデータを作成して、基本操作を確認してみましょう:
これを使って以下の操作をしてみます:
df.head() # 最初の5行を確認
df.info() # データ型や欠損の有無など構造を把握
df.describe() # 数値項目の統計情報を確認で全体像を確認できます。
▶️ 実行結果(df.head())
| 製品型番 | 測定値_硬さ | ロット番号 | 測定日 |
|---|---|---|---|
| AX100 | 95.2 | 101 | 2024-03-01 |
| AX100 | 97.5 | 101 | 2024-03-01 |
| BX200 | 88.0 | 102 | 2024-03-02 |
| BX200 | 90.1 | 102 | 2024-03-02 |
| CX300 | None | 103 | 2024-03-03 |
▶️ 実行結果(df.info())
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 5 entries, 0 to 4
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 製品型番 5 non-null object
1 測定値_硬さ 4 non-null float64
2 ロット番号 5 non-null int64
3 測定日 5 non-null object
dtypes: float64(1), int64(1), object(2)
memory usage: 288.0+ bytes▶️ 実行結果(df.describe())
測定値_硬さ ロット番号
count 4.000000 5.000000
mean 92.700000 101.800000
std 4.452812 0.836660
min 88.000000 101.000000
25% 89.525000 101.000000
50% 92.650000 102.000000
75% 95.825000 102.000000
max 97.500000 103.000000pandasで“クセのあるCSV”も見える化
現場や顧客データで使用するCSVファイルは一見キレイでも、よく見ると問題が隠れています:
- 測定ミスで NaN(欠損値) が混じっている
- ログの途中で値が飛んでいる
- 「この列、全項目NaNだけど本当に必要?」となるケース
欠損値のチェックには以下のようなコードを使います。
df.isnull().sum() # 各列の欠損数を確認✅ 欠損値への対応方法(pandas)
df = df.dropna() # 欠損のある行を削除
df = df.fillna(0) # 欠損を0で埋める(例:強度測定ミスなど)💬 現場エンジニアが実感するデータ活用の”あるある”
製造業のCSVデータには、NaN(欠損値)が混ざるのが当たり前。
特に「この列、全部NaNなんですけど?」という場面では、
- 本当にその項目が未使用なのか?
- それとも測定ミスや出力漏れなのか?
を見極める“データリテラシー”が求められます。
df.info()で各列の中身や欠損状況を確認df.describe()で統計的に異常値を見つける
「まずは構造確認から」──これがPythonによる**“現場データ処理の基本姿勢”**です。
3. 試験条件ごとにデータを集計しよう(pandas groupby 入門)
データを扱う上で、**「条件ごとの平均」や「件数の比較」**は分析の基本中の基本。
製造業の現場でも、
- 製品ごとの強度差は?
- ロットや工程ごとにばらつきがないか?
といった確認は、日常的な分析業務です。
🔢 製品別に平均値を出してみよう(pandas groupby())
df.groupby("製品型番")["測定値_硬さ"].mean()▶️ 実行結果:
製品型番
AX100 96.35
BX200 89.05
CX300 NaN
Name: 測定値_硬さ, dtype: float64👉 groupby() を使えば、製品や条件ごとの平均値や合計がすぐに計算できます。
🔢 ロットごとの件数を数える(value_counts())
df["ロット番号"].value_counts()▶️ 実行結果:
102 2
101 2
103 1
Name: ロット番号, dtype: int64👉 ロット番号ごとの件数や頻度を手軽に確認できるのが value_counts() の強み。
現場エンジニアが実感するデータ活用の”あるある”
「製品AとBで強度に差が出てるのはなぜ?」
「この工程だけ異常にばらつきが大きい…?」こうした**“比較・傾向分析”**は、集計でまず傾向を見てから、次のアクションを考える材料になります。
🧩 クロス集計も pivot_table() で一発
df.pivot_table(index="製品型番", columns="測定日", values="測定値_硬さ", aggfunc="mean")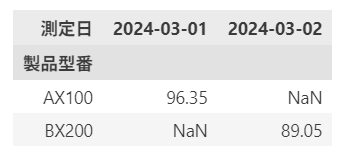
👉 クロス集計(ピボット集計)を使えば、製品×条件のような2軸の平均値比較も簡単にできます。
💡 groupby() / value_counts() / pivot_table() の3つは、
製造業のデータ分析でとにかく使う頻出関数です。
少量のデータからでも傾向が見えてくるので、最初の集計にぴったりです。
4. グラフで可視化してみよう(matplotlib / seaborn)
データの傾向やばらつきを把握するには、グラフで“見える形”にすることが一番わかりやすい方法です。
Pythonでは matplotlib や seaborn を使うことで、
製品ごとの比較や異常値の可視化を、わずか数行で実現できます。
import matplotlib.pyplot as plt
import seaborn as sns✅ よく使われるグラフの種類(製造業の現場でも活躍)
- 折れ線グラフ(時系列変化のトレンド把握)
- 箱ひげ図(ばらつきの可視化、工程比較に最適)
- ヒストグラム(分布の偏り、異常検出に活用)
ヒストグラムが「分布らしく」見えるように、先ほどのような製造業向けのダミーデータをロットごとに大量(例:各製品100件)に生成したものを使います。
import numpy as np
np.random.seed(42) # 再現性のための乱数固定
# 製品ごとに異なる分布で測定値を生成
data_ax = np.random.normal(loc=96, scale=2, size=100) # 製品AX100:平均96
data_bx = np.random.normal(loc=90, scale=1.5, size=100) # 製品BX200:平均90
data_cx = np.random.normal(loc=85, scale=3, size=100) # 製品CX300:ばらつき大
# 製品名を付ける
df = pd.DataFrame({
"ProductNumber": ["AX100"] * 100 + ["BX200"] * 100 + ["CX300"] * 100,
"MeasredValue": np.concatenate([data_ax, data_bx, data_cx])
})▶️ 箱ひげ図の例(seaborn)
sns.boxplot(x="製品型番", y="測定値_硬さ", data=df)
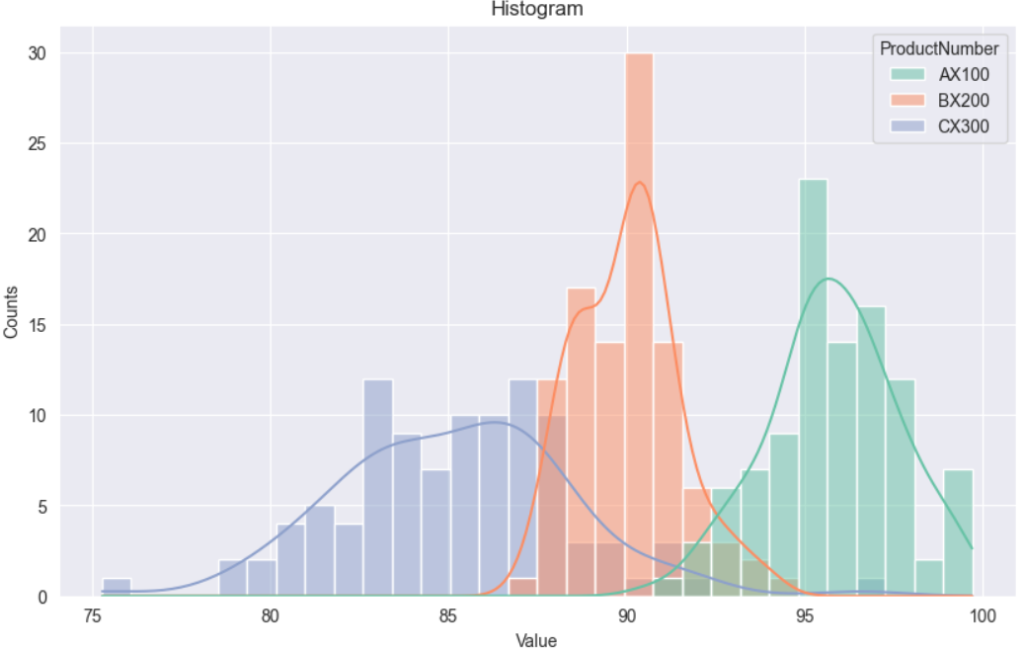
plt.savefig("boxplot.png") # グラフをPNGとして保存▶️ ヒストグラムの例(seaborn)
plt.figure(figsize=(10, 6))
sns.histplot(data=df, x="MeasredValue", hue="ProductNumber", bins=30, kde=True, palette="Set2")
plt.title("Histogram")
plt.xlabel("Value")
plt.ylabel("Counts")
plt.savefig("histogram_by_product.png")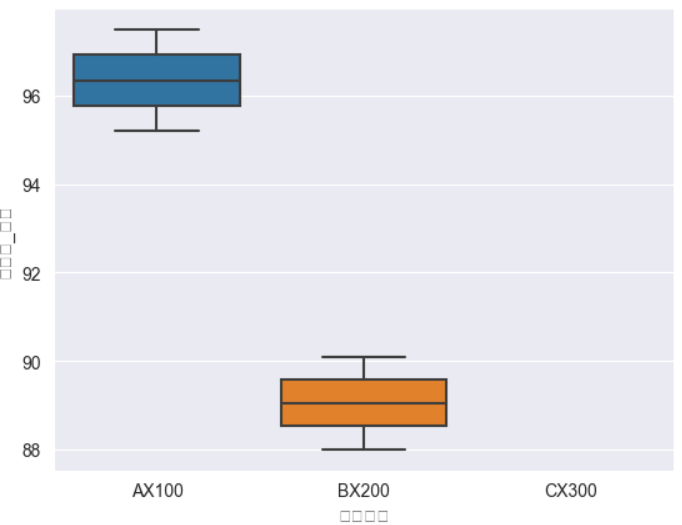
💡 seaborn は見た目がキレイで、報告資料にそのまま使えるクオリティのグラフが出力できます。
現場エンジニアが実感するデータ活用の”あるある”
箱ひげ図 / ヒストグラムは“ばらつきの傾向”を見るのに便利です。
測定値が基準に対してどの程度集中しているか、外れ値があるかなどを一目で確認できます。とくに**「どこで異常が起きているのか?」を探る初期分析**としてとても有効です。
5. 複数ファイルも処理できるようになると“最強の武器”に
今回の例では、1つのCSVファイルを使って集計や可視化を行いましたが、
実際の現場では「1日で10ファイル以上届く」なんて普通の話です。
🧾 よくある現場パターン:
- ロットごとにCSVファイルが分かれている(lot101.csv, lot102.csv…)
- 測定装置ごとに出力形式やファイル名がバラバラ
- フォルダ内のすべてのCSVを手作業で開いて集計している
💡 そんなときこそ、Pythonによる“複数ファイルの自動処理”が威力を発揮します。
# フォルダ内のCSVをまとめて読み込む(次回紹介予定)- 複数CSVを1つにまとめる(マージ・連結)
- 日付やロット番号で自動フィルタ
- 測定データを条件ごとに自動グラフ化
- レポート出力(PDF・Excel)まで一括で!
6. まとめと次回予告
おつかれさまでした。
今回は、測定データをPythonで読み込み → 確認 → 集計 → グラフ化するまでの基本的な流れを実践してきました。
✅ 振り返りポイント
- 現場の“あるある”なCSVファイル問題(文字化け・欠損・構造ズレ)への対処法
pandasを使ったデータ構造の把握と集計matplotlib/seabornによる可視化の基本操作- Excelでは面倒だった作業が、Pythonで一発処理できる快感
💡「Pythonってこんなに便利だったんだ」「思っていたより使えるかも」
…そう感じられた方は、もう次のステップに進む準備ができています!
🔜 次回予告:「複数CSVの一括処理とレポート自動化編」
- 📂 フォルダ内のCSVをまとめて読み込む
- 📊 測定日やロットごとにグラフを自動生成
- 📄 最終結果をExcelやPDFでレポート出力
“毎日手作業で繰り返していた集計・可視化・報告書作成”が、Pythonスクリプトで一発完了できる未来。
現場でそのまま使えるPythonのバッチ処理テクニックを、次回たっぷりお届けします。お楽しみに!


コメント