



🛠️【Python現場あるある】設定がバラバラで再現できない…を防ぐ構成術
「これ、どこでパラメータ変えてるの?」
「前回と同じ条件で再現できる?」
「ログ残ってない?進捗どこから説明すればいい?」
──製品開発の現場で、Pythonコードを使って何かを動かすとき、この手の質問が飛んできてたんです。(転職したばかりの私にはようわからん状態…)
そのたびに「あれ、どこだったかな…」と.pyファイルを開いて、print文をたどって、手探りで状態を再確認。
もう、効率も再現性もあったもんじゃない。
この状態でレビューや引き継ぎを迎えると、めちゃくちゃ気まずい。
「たしかにコードは動く。でも、構成がバラバラで全体像がつかめない」
──この“技術的に動いてるけど、実務では使いづらい状態”を抜け出すために、私は構成を見直すことにしました。
関連記事:「動くけど、読まれないコード。じゃ、それって意味ある?」は👇

📌 この記事で得られること
この記事は、こんな現場の“あるある”にモヤモヤしているエンジニアに向けて書いています:
- 条件変更のたびに.pyファイルを手で直してる
- 結果のログを取ってなくて、何やったか忘れる
- コードのどこから実行していいかわからなくなる
- 他の人に引き継ぐとき、毎回説明がしんどい
──全部、私が過去にやらかしてきたことです。
あとから動かした人が“同じ動作を再現できるか”が超重要。
にもかかわらず──
- 条件設定が.pyファイルにハードコーディングされている
- ログは残っておらず、printの履歴すらない
- main関数がなくて、どこから処理が始まるのか不明
そのとき鍵になったのが、
- yamlファイル(設定管理)
- logファイル(履歴管理)
- pyファイル(処理の分離)
- main.py(実行の入口)
この4つの役割を明確に切り分けてから、コードの再利用性も、説明のしやすさも、一気に改善したんです。
構成イメージ|「設定・処理・記録・司令塔」の4役を分担させるとこうなる
まずはこちらの図をご覧ください👇
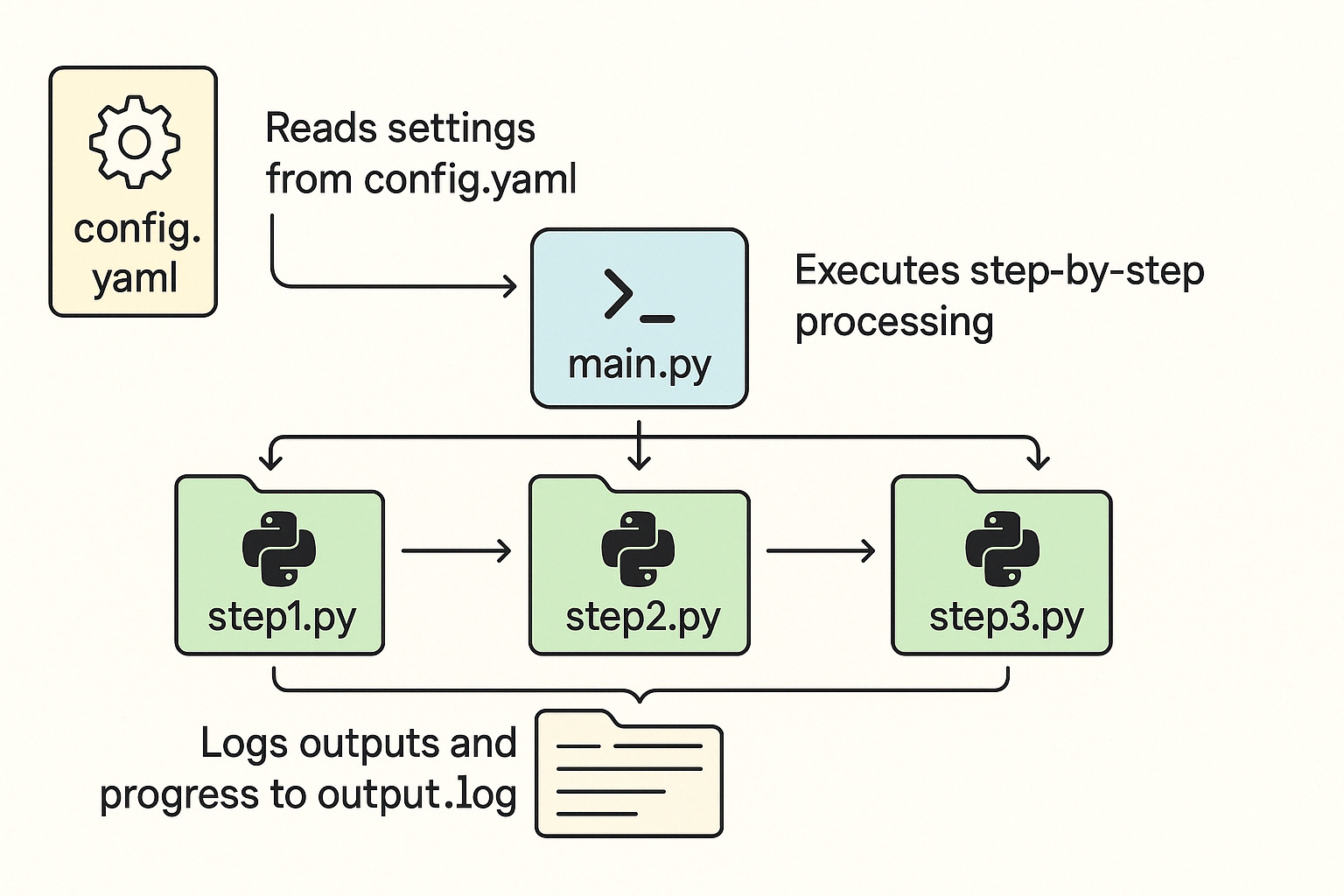
この構成は、私が製品開発の現場で辿り着いた「動かす・記録する・共有する」をスムーズに回すための最低限の仕組みです。
各ファイルの役割は次の通り:
config.yaml:すべての設定をここに集約(閾値、ファイルパス、出力先など)main.py:処理の流れを制御する実行ファイル。yamlを読み込み、順に処理を実行step1.py / step2.py / step3.py:処理内容ごとの部品(関数やクラスの集合体)output.log:処理の進行状況や結果を記録するログファイル
これだけで変わる、4つの実感
- 条件変更が怖くなくなる
→.pyを開かずに、yamlを変えるだけでOK。 - 説明がしやすくなる
→ 「このパラメータです」「ログに残ってます」と即答できる。 - 再利用と再現性が段違い
→ 過去の結果を比較・再実行が簡単。 - 他の人でも迷わず実行できる
→main.pyだけ動かせばいい。構造が明確。
このあと、各構成要素の具体的な使い方と注意点を、実体験ベースで一つずつ解説していきますね。
次は yamlファイル から見ていきましょう 💡
yamlファイル|設定変更は「コード直さず」で完結させたい
以前の私は、何かパラメータを変えたいとき──

当時はそれで十分だと思ってたんですが、何度かこういう場面に直面したんです:
- 再現したい条件があるけど、前回の設定を忘れてる
- 他の人が使うとき、「どこを変えればいいか」が分かりにくい
- パラメータをいじったつもりが、間違ってコードの処理本体を壊してしまう
つまり──
「動かすための変更」と「設計のロジック」が混ざってしまっていたんですね。
💡 yamlで切り出したら、全部ラクになった

こうして外部ファイルで管理すれば、
- 設定だけ変えたいときにコードを触らなくて済む
- Gitで履歴も見やすいし、条件の比較もできる
- 他の人に「このyaml編集してね」と言えるだけで説明コストが激減
開発中はもちろん、本番環境での自動実行や条件バリエーションの試行にもめちゃくちゃ便利でした。
詳細な使い方はこちらの記事で紹介👇

logファイル|print()の限界に気づいたあの日
正直に言います。
昔の私は、ログなんてprint()で十分だと思ってました。
「今〇〇してます」「この値出ました」──
コンソールにベタベタ出して、それをスクショして満足。
でも、そのうち気づくんですよね。
「あれ、前回の実行って、どんな条件だったっけ?」
「このprint、どの関数から出てきたやつだっけ?」
📝 printだけじゃ追えない、あの現場の混乱
製品開発の現場って、毎回ちょっとずつ条件が変わるんです。
- センサの閾値が微妙に違う
- 入力ファイルが日によって異なる
- パラメータをテスト中にいじる
なのにログを残していなかったせいで、再現できない・報告できない・説明できないの三重苦。
私は何度も、「前と同じ条件で動かして」と言われて詰みました。
✅ logファイルに出力するだけで、未来の自分が救われる
それからは、loggingモジュールを使って、毎回の実行ログをファイルに残すようにしました。
🧩 logging.basicConfig() の役割と、ログに何を書くかの関係性
① basicConfig() の設定=“ノートのルール”

これは言ってみれば、
「ログを
output.logに記録してね。時間付き・レベル付きのフォーマットでお願い」
という準備段階の宣言です。
② logging.info() などのログ関数=“実際の書き込み内容”

📌 最低限、これだけはログに残すと救われるリスト:
- 🕒 実行時刻(いつやったのか)
- 🔧 使用パラメータ(閾値やハイパーパラメータ)
- 📈 中間結果・重要指標(例えばF1スコアやMAEなど)
- ✅ ステップの進行状況(どこまで処理が終わったか)
- ⚠️ エラー内容・警告(トラブル時の手がかり)
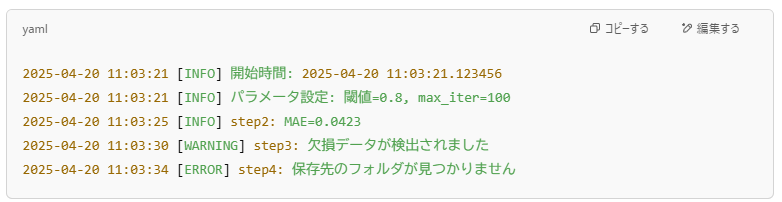
これを残しておくだけで──
「誰が」「いつ」「何を使って」「どうなったか」がひと目で分かります。
特に製品開発のような長期プロジェクトでは、**“ログ=記憶の代わり”**みたいな存在。
まとめるとこうなります:
| 役割 | 例 | 意味 |
|---|---|---|
| ログの書式と場所の設定 | logging.basicConfig() | どこにどう記録するかのルール決め |
| ログの書き込み内容 | logging.info(), logging.warning() など | 何を記録するかの実際の中身 |
実際のレビューでも「ログある?」で安心された話
レビューや上司への報告時にも、
**「logファイルあります」「そこに全部出てます」**って言えるだけで、信頼感が変わるんですよね。
print文をスクロールして探すより、
ログファイルを添付する方が早いし、何より**「ちゃんと考えて動かしてる感」**が出る。
pyファイル:処理は“機能ごとに分けておく”と後がラク
Pythonスクリプトを書いていると、最初は「全部1ファイルでええやん」と思いがち。
でも実際は、時間が経つほどこうなります。
- どこに何の処理があるか分からない
- あとから一部だけ試そうとしても切り出せない
- 同じ処理を別の場所でもう一度コピペしてる
私は以前、異常検知モデルを作っていたとき、
前処理、モデリング、評価、可視化を全部ひとつのipynbファイル に書いていました。
結果、何が起きたかというと──
💥「実行したい部分だけ動かすのがめちゃくちゃ面倒!」
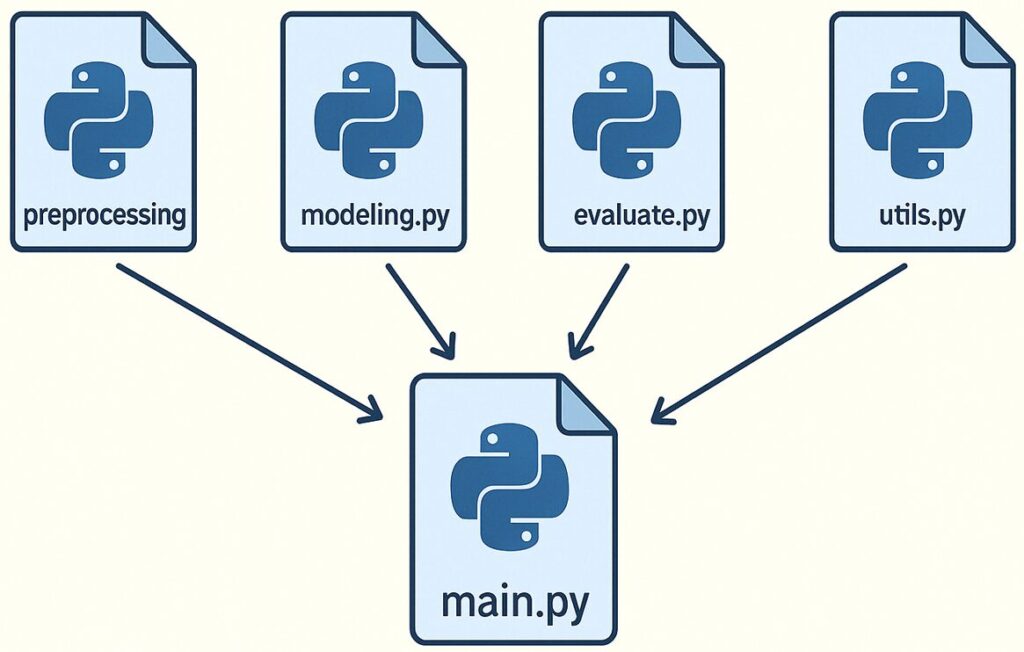
🧠 main.py の参考コード
# main.py
import logging
from datetime import datetime
from preprocessing import load_data, preprocess
from modeling import train_model, save_model
from evaluate import evaluate_model
# ログ設定
logging.basicConfig(
filename='output.log',
level=logging.INFO,
format='%(asctime)s [%(levelname)s] %(message)s'
)
def main():
logging.info("処理を開始します")
logging.info(f"開始時刻: {datetime.now()}")
# データ読み込み
try:
df = load_data("data/raw_data.csv")
logging.info("データの読み込みが完了しました")
except Exception as e:
logging.error(f"データの読み込みに失敗しました: {e}")
return
# 前処理
df_processed, X, y = preprocess(df)
logging.info("前処理が完了しました")
# モデル学習
model = train_model(X, y)
logging.info("モデルの学習が完了しました")
# モデル保存
save_model(model, "models/model.pkl")
logging.info("モデルの保存が完了しました")
# 評価
metrics = evaluate_model(model, X, y)
logging.info(f"評価結果: {metrics}")
logging.info("処理が正常に終了しました")
if __name__ == "__main__":
main()
分け方の目安(私の場合)
実際に整理して効果があった構成は、以下のような感じです:
| ファイル名 | 役割 |
|---|---|
preprocessing.py | データ読み込み、クリーニング処理 |
modeling.py | 学習・予測モデルの構築ロジック |
evaluate.py | 評価指標の計算(MAE、R²など) |
utils.py | 汎用関数(例:ログ保存、パス生成) |
それぞれの関数は、小さくまとめて**「このファイルにあるもの=この処理」**がすぐわかるようにしておきます。
現場での実感
関数化してファイルを分けるようになってからは──
- あとから検証や追加実験をしやすくなった
- 他の人に一部だけ渡せるようになった
- バグが起きても、どこを見ればいいかすぐわかる
しかも、レビュー時にも「この処理どこ?」と聞かれたら、 modeling.py のこの関数です って一発で示せるので便利。
まとめ:「誰かに見せる前提」でコードを整える
Pythonコードは「動けばいい」じゃない。
**“読まれて使われてナンボ”**です。
- 自分で見返して分かる
- 他人に引き継げる
- 論理が整理されてる
この3つがそろって、初めて「実務で使えるPythonコード」になる。
そのために── “伝わる構成”を、ChatGPTや構成の工夫で整えることを、ぜひ試してみてください。


コメント