



「printで十分」は卒業しよう|Python開発でログを残すべき理由
昔の私は、Pythonでログを残すなんて意識すらしていませんでした。

──はい、完全にコンソールにベタ出し派。
そのまま実行結果をスクショしてSlackに貼る。 あるいは、表示された数値をメモ帳に手打ちで残す。
いや、それ開発じゃなくて“手作業レポート”でしょって今なら思います。
でも当時は、それで十分だと思ってたんです。 “とりあえず動いて結果が出ればいい”と。
けど、ある日こんな質問を投げられて詰みました。
「で、前回ってどの条件で回したんですか?」
「その数値、どこかに残ってます?」
……うっ。
過去の出力、全部流れて消えてました。
結果的に、「どのコードで、どんなパラメータで、何が出たか」がすべて不明。 上司にもチームにも説明できず、ひとりだけ“記憶を頼りに探索する探偵モード”になっていました。

📌 この記事で得られること
この記事では、こんな経験のあるエンジニアに向けて:
- printだけでログを済ませてたけど、あとで困ることが増えてきた
- 実行条件の履歴が残ってなくて、報告も再現もできない
- コードレビューで「実行履歴ありますか?」と聞かれて焦った
- 「どこまで処理が進んだのか」が分からなくて、デバッグに時間がかかる
──こうした課題を、ログファイル(log)で一発解決できた話をお届けします。
しかも、ChatGPTとのやりとりで「ログって、開発の意思表示なんだ」と気づけたのが大きな収穫でした。
🤖 もちろん、main.pyでのサンプルコードもお渡しします!
Python開発をしているなら、きっと「なるほど」があるはずです。
📂 loggingも活用して全体の再現性・保守性を良くしたい方は👇

🤖 ChatGPTに「printって限界あるよね?」と聞いてみた
このような経緯があり、私は、ChatGPTにこう聞きました。
「printでログ管理してるんですけど、ちょっと限界感じてます。いい方法ありますか?」
🤖 ChatGPT:
「Pythonの logging モジュールを使うと、実行履歴をファイルに記録できます。printよりも構造化された出力が可能です」
──logging?それ何者?状態の私は、さらに聞いてみました。
🔧 logging の基礎を教えてもらった(そして即採用)
main.pyと合わせた「サンプルコード」は次のセクションに記載してます
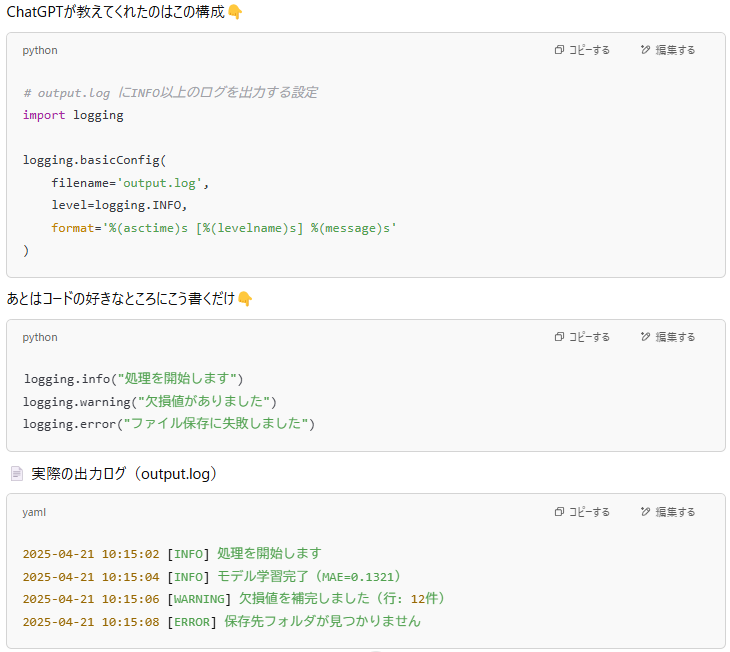
──いや、これ、めちゃくちゃ安心感あるし便利。
ChatGPTに聞いて分かった「ログに最低限残すべきもの」
ChatGPTとのやりとりで、「どんなログを残せば未来の自分が助かるか?」も整理できました👇
✅ 実行時刻
✅ 使用パラメータ(yamlなどと連携)
✅ 処理ステップの通過記録
✅ 中間結果(精度やスコア)
✅ エラーや例外の詳細
実際にこれを出すようにしてから、
- 上司に「logファイル見れば一発です」で済む
- 仕様変更しても履歴があるから比較しやすい
- どこで止まったか、logで即特定できる
──ようになりました。
🧪loggingの定義と書き方の役割整理
| 役割 | 内容 |
|---|---|
logging.basicConfig() | ログの出力先・レベル・フォーマットを定義(設定ファイル的) |
logging.info() | 実際の記録。処理開始、成功など |
logging.warning() | 軽微な異常や補正情報 |
logging.error() | 重大な失敗や例外 |
📂 ファイル構成の見通しをさらに良くしたい方は👇

やってよかったログ運用ルール(ChatGPTとの壁打ちまとめ)
- 📁 output.log だけ用意すればOK
- 🎯 実行ごとにログを初期化 or 追記(使い分け)
- 🔍 レベル分け(INFO / WARNING / ERROR)で見やすく
- 🧩 loggingのセットは main.py で共通化
# main.py
import logging
from datetime import datetime
from config_loader import load_config
from preprocessing import load_data, preprocess
from modeling import train_model, save_model
from evaluate import evaluate_model
# === ログのセットアップ(ここで一括定義) ===
logging.basicConfig(
filename='output.log',
level=logging.INFO,
format='%(asctime)s [%(levelname)s] %(message)s'
)
def main():
logging.info("処理を開始しました")
logging.info(f"実行開始時刻: {datetime.now()}")
# 設定の読み込み
try:
config = load_config()
threshold = config["threshold"]
max_iter = config["max_iter"]
data_path = config["data_path"]
logging.info(f"パラメータ設定: threshold={threshold}, max_iter={max_iter}, data_path={data_path}")
except Exception as e:
logging.error(f"設定ファイルの読み込みに失敗: {e}")
return
# データの読み込み
try:
df = load_data(data_path)
logging.info(f"データ読み込み成功: {len(df)}件")
except Exception as e:
logging.error(f"データ読み込みに失敗: {e}")
return
# 前処理
try:
df_processed, X, y = preprocess(df, threshold)
logging.info("前処理完了")
except Exception as e:
logging.error(f"前処理に失敗: {e}")
return
# モデル学習
try:
model = train_model(X, y, max_iter=max_iter)
logging.info("モデル学習完了")
except Exception as e:
logging.error(f"モデル学習に失敗: {e}")
return
# モデル保存
try:
save_model(model, config["model_path"])
logging.info(f"モデル保存完了: {config['model_path']}")
except Exception as e:
logging.error(f"モデル保存に失敗: {e}")
return
# 評価
try:
metrics = evaluate_model(model, X, y)
logging.info(f"評価結果: {metrics}")
except Exception as e:
logging.error(f"評価処理に失敗: {e}")
return
logging.info("処理が正常に終了しました")
if __name__ == "__main__":
main()🔍 実務でのポイント:
logging.basicConfig()は必ずスクリプトの最上部で設定(main.py で統一)- 処理の流れをログで“なぞれる”よう、前後の記録をセットで残す
try-exceptで各処理の失敗時ログもカバー- YAML で読み込んだパラメータもログに記録しておくと、後で比較や報告がしやすい
まとめ:ログは「記録」ではなく、「自分へのメッセージ」
昔の私は、**「ログ=エラーが起きたときだけ見るもの」**と思っていました。
でも今は、
- なぜその値で動かしたのか
- どういう結果が出たのか
- どこで止まったのか
──をすべて記録しておくことで、「次の行動が早くなる」んです。
ChatGPTとのやりとりで気づいたのは、
**「ログは過去の証拠じゃなく、未来のヒント」**だということ。
「今このコードを使っている自分が、未来の自分に何を伝えておきたいか?」
そんな視点でログを書けるようになったのは、ChatGPTのおかげです。


コメント