




はじめに
製造業の研究開発現場では、試験機や測定器から日々膨大なデータが出力されます。
最初のうちは、目視チェックやExcelでグラフを作成して確認する──
そんな運用でも、データ量が少ないうちはなんとか回っていました。
しかし、試験件数が増え、測定ラインが増え、
月に数百件、数千件というデータが積み上がる中で、
**「本当に異常が起きていないか?」**を確かめ続けることは、限界を迎えます。
私自身は、こうしたデータを日常的にチェックしていたわけではありません。
顧客現場の課題を発見するために、
測定データの中から**「見えない異常の兆し」や「潜在的なリスク」**を早期に捉える必要がありました。
その一環として、
**「時系列データのトレンド処理や異常検知」**についてPythonで学び、
実際に手を動かして試行錯誤してきた知見をまとめたのがこの記事です。
✅ この記事でわかること
- 製造業の現場で異常検知が求められる背景
- 平均±3σルールによるシンプルなしきい値異常検知の考え方
- Python(pandas、matplotlib)を使った異常検知の実装手順
- 測定データをグラフ化して異常を一目で見抜く方法
ただし、正直なところ、
単純なしきい値判定(平均±3σ)だけでは、現場の異常を完全に捉えることはできません。
現場で本当に求められる異常検知には、
- トレンド変化を捉える
- 複雑なパターン異常を見抜く
- 未来予測を活用する
といった、より高度なアプローチが必要になります。
それでも──
まずは、
「Pythonで異常検知の基礎を押さえる」
ことが、すべてのスタートです。
この記事では、
最もシンプルなしきい値ベース(平均±3σ)による異常検知を、
Pythonを使って現場視点でやさしく実装していきます。
Python初心者でも安心して取り組める内容になっていますので、
現場データを扱いながら、「顧客課題を見つける力」を育てる第一歩として、ぜひ参考にしてみてください。
1. 異常検知とは?
異常検知とは、
**「通常とは異なるパターンや挙動を、データの中から早期に見つけ出す技術」**を指します。
製造業の現場では、異常検知が求められるシーンが数多く存在します。
たとえば──
- 測定機器の故障予兆を捉える
- 製品品質のばらつきを早期に発見する
- プロセス異常を検知してトラブルを未然に防ぐ
これらに共通しているのは、
**「異常は早く気づければ気づけるほど、大きな損失や手戻りを防げる」**という現場ニーズです。
しかし、実際には──
- 測定値は常にばらつきがあるのが当たり前
- 人間の目では微細なパターン変化を見抜ききれない
- データ量が多すぎて、手作業では到底追いつかない
といった現実が立ちはだかります。
だからこそ、
Pythonなどを活用し、異常を「データから機械的に見つけ出す」技術が、
製造業現場の改善や顧客課題発掘において、ますます重要になってきています。
製造業データの特徴と異常検知の難しさ
製造業の測定データには、異常検知を難しくする特有の性質があります。
- ノイズが多い(計測環境や人の操作誤差)
- ばらつきがあるのが正常(常に一定値になるわけではない)
- 異常発生頻度が極めて低い(だからこそ検出が難しい)
このため、単にデータを眺めるだけでは、
「どこまでを正常とみなし、どこからを異常と捉えるか」
を慎重に判断する必要があります。
今回紹介する「平均±3σルール」による異常検知は、
こうした製造業データのばらつきの中から、
明らかに外れた挙動をシンプルに検出するための最初のアプローチとなります。チです。
2. まずはシンプルな異常検知から始めよう(平均±3σルール)
異常検知と聞くと、
「機械学習モデルを作らなきゃいけない?」「複雑なアルゴリズムが必要?」と身構えてしまうかもしれません。
でも、最初から難しいことをやる必要はありません。
まずは、平均値と標準偏差を活用した、
シンプルなしきい値検知からスタートするのが現実的です。
平均±3σルールとは?
平均±3σルールとは、
**データの「中心」と「ばらつき」**をもとに、異常を検出する基本的な考え方です。
- 平均値 ± 3 × 標準偏差の範囲内 → 正常
- それを超えるデータ → 異常とみなす
このルールは、データが正規分布に近い場合、
**99.7%**のデータがこの範囲に収まる、という性質を利用しています。
つまり、
「平均±3σを超えるデータは、かなり異常な動きをしている可能性が高い」
というシンプルな指標になります。
シンプル手法の強み
- 計算が早い(リアルタイム対応も可能)
- 実装が簡単(Python初心者でもすぐ試せる)
- 傾向を押さえるには十分強力
もちろん、
製造業の測定データは必ずしも理想的な正規分布ではありません。
それでも、
「まず異常を拾い上げる」という目的には、このシンプルな手法が非常に有効です。
測定値だけでなく「標準偏差」も見るべき理由
実際の現場データでは、
単に測定値が上下するだけでなく、ばらつき(標準偏差)が異常に広がったり、縮まったりするケースもよく起こります。
たとえば──
| パターン | 問題点 |
|---|---|
| 平均値は正常範囲内 | でもばらつき(標準偏差)が急に大きくなっている |
| 測定値に大きな変動はない | でもプロセスが不安定になっている |
こういった現象は、
標準偏差の異常監視を取り入れないと見逃してしまいます。
だから今回のシンプル異常検知でも、
測定値の逸脱だけでなく「標準偏差の異常変動」も同時にチェックする設計を取り入れます。
標準偏差しきい値設定の考え方
- 通常時の標準偏差に対して、±20%程度の許容範囲を設ける
- 具体例:
- 標準偏差が通常の1.2倍以上 → 異常(ばらつき拡大)
- 標準偏差が通常の0.8倍以下 → 異常(ばらつき収束しすぎ)
こうすることで、
単純な測定値の異常だけでなく、
プロセスの安定性悪化も早期に検知できるようになります。
3. Pythonでしきい値ベースの異常検知を実装する
ここからは、
実際にPythonを使って、測定値のしきい値判定+標準偏差のしきい値判定を行っていきます。
まずは、ダミーデータを作成し、
手順をひとつずつ確認しながら進めましょう。
使用するライブラリ
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlibpandas:データ操作numpy:ダミーデータ生成matplotlib:グラフ可視化japanize_matplotlib:日本語グラフ対応
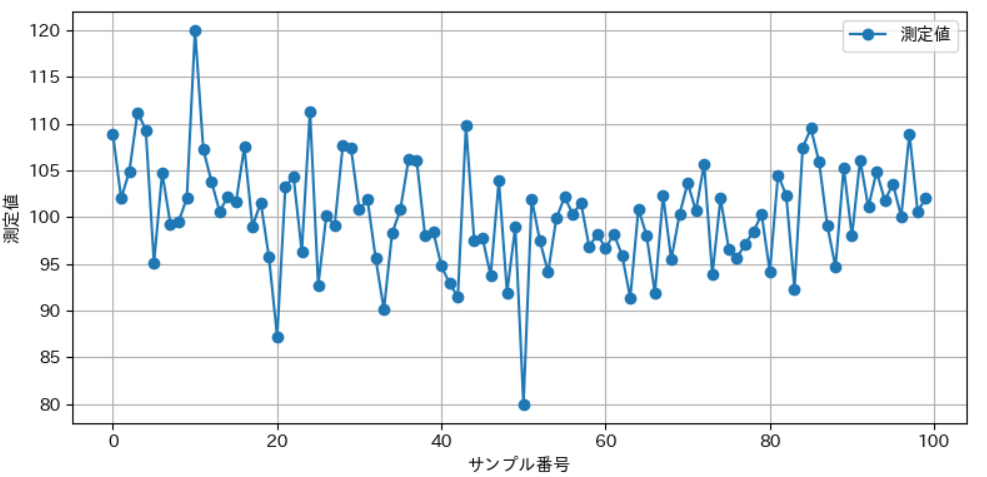
ダミーデータを作成する
まずは、正常データ+異常データを適当に混ぜたダミーデータを作ります。
# 乱数シード固定(再現性確保)
np.random.seed(0)
# 平均100、標準偏差5の正規分布データを生成
data = np.random.normal(100, 5, 100)
# 故意に異常値を混ぜる
data[10] = 120 # 異常値(高すぎ)
data[50] = 80 # 異常値(低すぎ)
# データフレームに格納
df = pd.DataFrame(data, columns=["測定値"])
✅ この時点で、「正常なデータ」と「明らかな異常データ」が混在しています。
データのイメージはこんな感じ👇
測定値のしきい値を設定する(平均±3σ)
次に、測定値に対して異常かどうかを判定するためのしきい値を設定します。
# 平均と標準偏差を計算
mean = df["測定値"].mean()
std = df["測定値"].std()
# 測定値のしきい値設定
upper_value = mean + 3 * std
lower_value = mean - 3 * std
print("上限値:", upper_value)
print("下限値:", lower_value)
実際の結果はこんな感じ👇

✅ このしきい値を超えた測定値を「異常」とみなします。
標準偏差のしきい値も設定する
次に、データ全体のばらつき(標準偏差)が異常に広がったり縮まったりしていないかも監視できるようにします。
pythonコピーする編集する# 標準偏差の許容範囲(±20%許容する例)
std_upper_threshold = std * 1.2
std_lower_threshold = std * 0.8
実際の結果はこんな感じ👇

✅ ばらつき自体が大きく変化している場合も、異常検知対象にします。
測定値と標準偏差で異常判定する
実際に、しきい値を超えたデータを検知していきます。
# 測定値の異常判定
df["測定値異常"] = (df["測定値"] > upper_value) | (df["測定値"] < lower_value)
# 全体の標準偏差をチェックしてばらつき異常判定
current_std = df["測定値"].std()
std_abnormal = (current_std > std_upper_threshold) or (current_std < std_lower_threshold)
# 標準偏差異常を一括フラグ(全体判定なので列には入れない)
print(f"標準偏差異常検知:{std_abnormal}")
✅ 測定値の個別異常と、全体ばらつき異常の両方を検出します。
測定値としきい値をグラフで可視化する
異常がどこで発生しているかを直感的に把握できるように、グラフ化してみましょう。
plt.figure(figsize=(10,6))
plt.plot(df["測定値"], marker="o", label="測定値")
plt.axhline(upper_value, color="red", linestyle="--", label="上限しきい値")
plt.axhline(lower_value, color="blue", linestyle="--", label="下限しきい値")
plt.title("測定値と異常検知(しきい値ベース)")
plt.xlabel("サンプル番号")
plt.ylabel("測定値")
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
実際の結果はこんな感じ👇
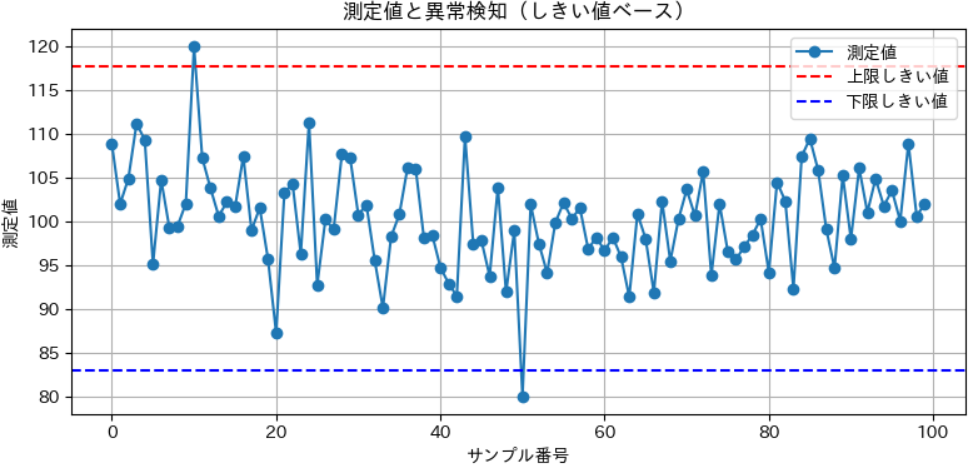
✅ 異常に飛び出しているデータポイントが、視覚的にすぐわかります!
✨ ここまででできたこと
| 項目 | やったこと |
|---|---|
| ダミーデータ作成 | 測定値+異常混ぜ込み |
| 測定値しきい値設定 | 平均±3σで上下限を設定 |
| 標準偏差しきい値設定 | ±20%許容範囲でばらつき監視 |
| 異常検知 | 測定値異常+ばらつき異常を検出 |
| グラフ可視化 | 測定値としきい値をビジュアル化 |
4. 手作業との違いとメリット
Pythonを使って異常検知を自動化することで、得られるメリットは明確です。
| 項目 | 内容 |
|---|---|
| ミス防止 | どんなにデータが増えても、判定精度がブレない |
| 時間短縮 | 100件でも1000件でも、数秒でチェック完了 |
| 初動対応の速さ | 異常を見つけ次第、すぐ次のアクションへ |
| 作業負担軽減 | 目視作業から解放され、データ分析に集中できる |
単純な異常検知でも自動化するだけで、現場の負担とリスクは大幅に減らせます。
ただし、現場で本当に求められるもの
今回紹介した**「測定値や標準偏差の逸脱を見つけるシンプルな検知」**は、
異常検知の第一歩として非常に有効です。
ですが、実際の現場で本当に求められるのは──
- なぜ異常が発生したのか?
- その兆候をもっと早く捉えられなかったのか?
という、
異常の要因特定
異常の予兆発見
です。
単に「異常が起きた」という事実だけではなく、
- 測定値のトレンドを見極め、
- 微妙な傾向変化を察知し、
- 未来予測と比較してズレを検出する、
そんな一歩先を読む力が、現場では求められます。
人間とPython、それぞれの強みを活かす
異常の要因特定や予兆発見は、
もともとは人間の感覚や経験に強く依存していました。
- 「このばらつき、普段と違う気がする」
- 「このトレンド、ちょっとおかしいかも」
こうした微妙な違和感を、
Pythonで数値化・モデル化することで、形にしていきます。
さらに、Pythonなら──
- 人間の目では気づかない微細なパターン変化
- 長期トレンドのわずかなズレ
も機械的に検知することができます。
つまり、
人間とPython、それぞれの強みを活かして補完し合うことが、現場の異常検知を進化させるカギになります。
ことが、現場で本当に意味のある異常検知を作り上げるカギになります。
5. まとめ|異常検知はまず「シンプルでいい」
異常検知と聞くと、
つい「機械学習」「高度なAI」といった難しいイメージを抱きがちです。
ですが、製造業の現場でまず求められるのは、
シンプルでもいいから、確実に異常を拾うことです。
- 測定値の異常を検知する
- 標準偏差の異常を見逃さない
- 小さな兆候に気づく
こうした**「小さな一歩」**を積み重ねることが、
最終的には、現場改善や顧客課題発掘につながっていきます。
✅ 小さく始めて、大きく育てる
今回紹介した
**「平均±3σルールによるシンプルなしきい値異常検知」**は、
異常検知の第一歩として非常に有効です。
もちろん、これだけで現場のすべての異常を網羅できるわけではありません。
ですが、
ここからスタートしなければ、
- 異常の要因特定
- 予兆の早期検知
- トレンド変化の察知
といった、
より高度な異常検知への挑戦も進みません。
Pythonを使って、
- 見える異常を確実に拾う
- ばらつきの異常にも気づく
こうした小さな積み重ねが、
やがて「現場を支える異常検知スキル」へとつながっていきます。
最初は小さく、でも確実に一歩ずつ進める。
この考え方を持って、Pythonによる異常検知に取り組んでいきましょう。
✅ 次回予告|現場データに適用してみる
次回は、
今回学んだシンプルな異常検知手法を、
実際の測定データ(ダミーデータ)に適用していきます。
- 複数ロット・複数試験データをまとめて読み込み
- フォルダ内CSVファイルを一括処理
- 実際に異常を検知し、グラフで可視化する
製造業の現場を想定したリアルなデータ処理フローを、わかりやすく解説します。
ぜひ、次回もご期待ください!


コメント