




はじめに
製造業の研究開発現場では、試験機や測定器から毎日のようにCSVファイルが出力されます。
最初はファイルをひとつずつ開き、手作業でコピペし、グラフ化して──
それでも、なんとか業務は回せていました。
しかし、
試験数が増え、ライン数が増え、
月に100枚、200枚と測定ファイルが溜まっていくと、
もう手作業では追いつかなくなります。
「この作業、Pythonで自動化できないか?」
そう考え、実際に現場で使ったスクリプトをベースに、
今回の記事では複数のCSVファイルをまとめて処理する方法を紹介します。
製造業エンジニア向けに、現場視点でわかりやすく解説していきますので、
ぜひ参考にしてください。
📂 Pythonの基本文法をまずは知りたい方は👇

✅ 本記事でわかること
- フォルダ内の複数CSVファイルを一括で読み込む手順(glob × pandas)
- ファイル名から試験日やロット番号を抽出するコツ
- まとめたデータを効率よく集計・グラフ化する流れ
- Python初心者でも取り組みやすい実践的アプローチ
それでは、始めましょう!
1. 複数CSVファイルを一括で処理する全体像
今回のゴールはシンプルです。
- フォルダ内に保存されたCSVファイルを
- Pythonで自動的に読み込み
- データをまとめ、集計・グラフ化まで完了する
必要なライブラリも標準的なものだけでOKです。
2. 必要なPythonライブラリをインポート(日本語対応込み)
まずは、使用するライブラリをまとめてインポートしておきます。
グラフで日本語が使えるよう、japanize_matplotlibも読み込みます。
pythonコピーする編集するimport pandas as pd
import matplotlib.pyplot as plt
import glob
import os
import japanize_matplotlib # 日本語対応
✅ ポイント
glob:フォルダ内のファイル取得に使用pandas:データ加工・分析用matplotlib:グラフ描画用(japanize_matplotlibで日本語対応)
3. フォルダ内のCSVファイルをまとめて取得する
対象フォルダに保存されたCSVファイルを、まとめて取得します。
pythonコピーする編集する# 測定データが保存されているフォルダパス
folder_path = "C:/data/measurement/2025_04/"
# フォルダ内のCSVファイルをすべて取得
csv_files = glob.glob(folder_path + "*.csv")
# 取得できたファイル一覧を確認
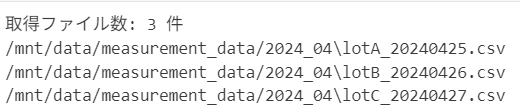
print(f"取得ファイル数: {len(csv_files)} 件")
for file in csv_files:
print(file)
実際の結果はこんな感じ👇
✅ ポイント
- フォルダパスは環境に合わせて設定
- 取得できたファイル数を確認し、漏れがないかチェック!
4. CSVファイルを読み込み、ロット番号と試験日を付加する
取得したCSVファイルを一つずつ読み込み、
ファイル名からロット番号と試験日をデータに付け加えます。
pythonコピーする編集する# 各ファイルのデータを格納するリストdisplay
df_list = []
for file in csv_files:
df = pd.read_csv(file)
# ファイル名からロット番号と試験日を取得
filename = os.path.basename(file)
lot, date = filename.replace(".csv", "").split("_")
df["ロット番号"] = lot
df["試験日"] = pd.to_datetime(date, format="%Y%m%d")
df_list.append(df)
# すべてのデータを1つにまとめる
combined_df = pd.concat(df_list, ignore_index=True)
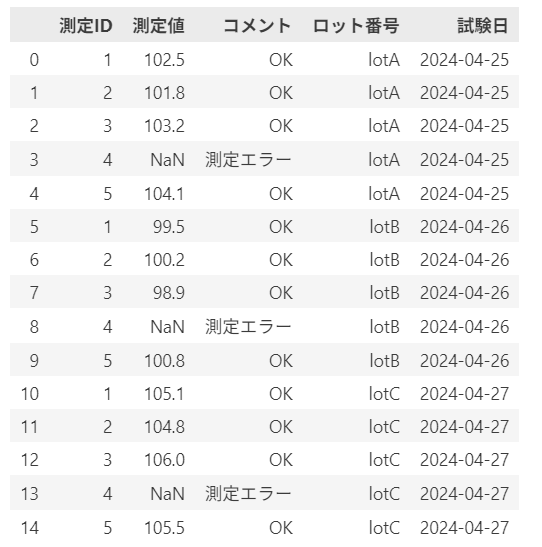
# データ確認(combined_df)
実際の結果はこんな感じ👇
✅ ポイント
- ファイル名は「ロット番号_日付.csv」形式を前提
試験日はdatetime型に変換しておくと集計・可視化がスムーズ
5. 欠損データ(NaN)を除外して、試験日ごとに測定値の平均を計算する
測定データには、機器エラーなどによる欠損(NaN)が含まれることがあります。
これを除外してから平均を取ります。
pythonコピーする編集する# 測定値がNaNのデータを除外
valid_data = combined_df.dropna(subset=["測定値"])
# 試験日ごとの測定値平均を計算
mean_values = valid_data.groupby("試験日")["測定値"].mean()
# 集計結果を確認
print(mean_values)
実際の結果はこんな感じ👇

✅ ポイント
- 欠損データを除くことで、正しい集計が可能になります
- 実際の現場でも、NaN処理は必須!
6. 測定値平均の推移を日本語対応グラフで可視化する
集計した平均値を、グラフで可視化します。
pythonコピーする編集するplt.figure(figsize=(10,6))
mean_values.plot(marker="o", linestyle="-")
plt.title("試験日別 測定値平均推移")
plt.xlabel("試験日")
plt.ylabel("測定値(単位)")
plt.grid(True)
plt.tight_layout()
plt.show()
実際の結果はこんな感じ👇
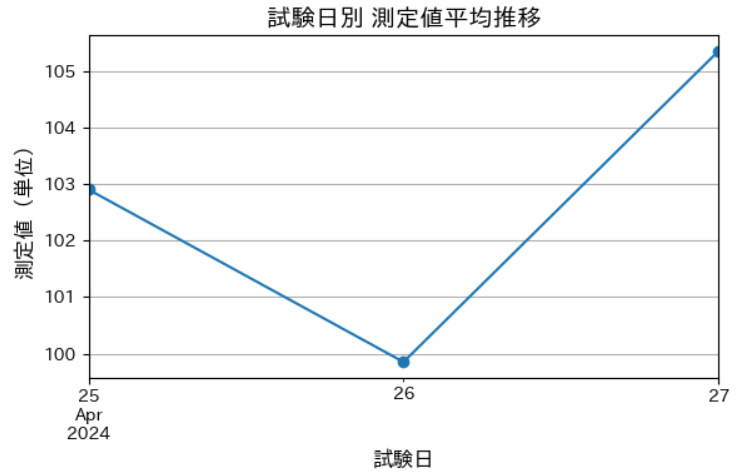
✅ ポイント
japanize_matplotlibのおかげで、タイトル・ラベルも自然な日本語に!- データポイント(marker=”o”)をつけると推移がわかりやすくなります
📂 Pythonで箱ひげ図やヒストグラムの描き方を知りたい方は👇
7. まとめ|測定データの一括処理で現場の作業負担を減らす
今回紹介した手順により、
バラバラだった測定データをPythonで一括処理し、
効率的に集計・可視化できるようになりました。
製造業の研究開発現場では、
データを「集めること」よりも、
**「意味を見出し、改善に活かすこと」**が求められます。
繰り返し作業をPythonで自動化することで、
より本質的な業務に集中できるようになります。
次回は、さらに応用編として、
異常値検出やレポート自動生成にも挑戦していきます!
ぜひ引き続きご覧ください!


コメント