



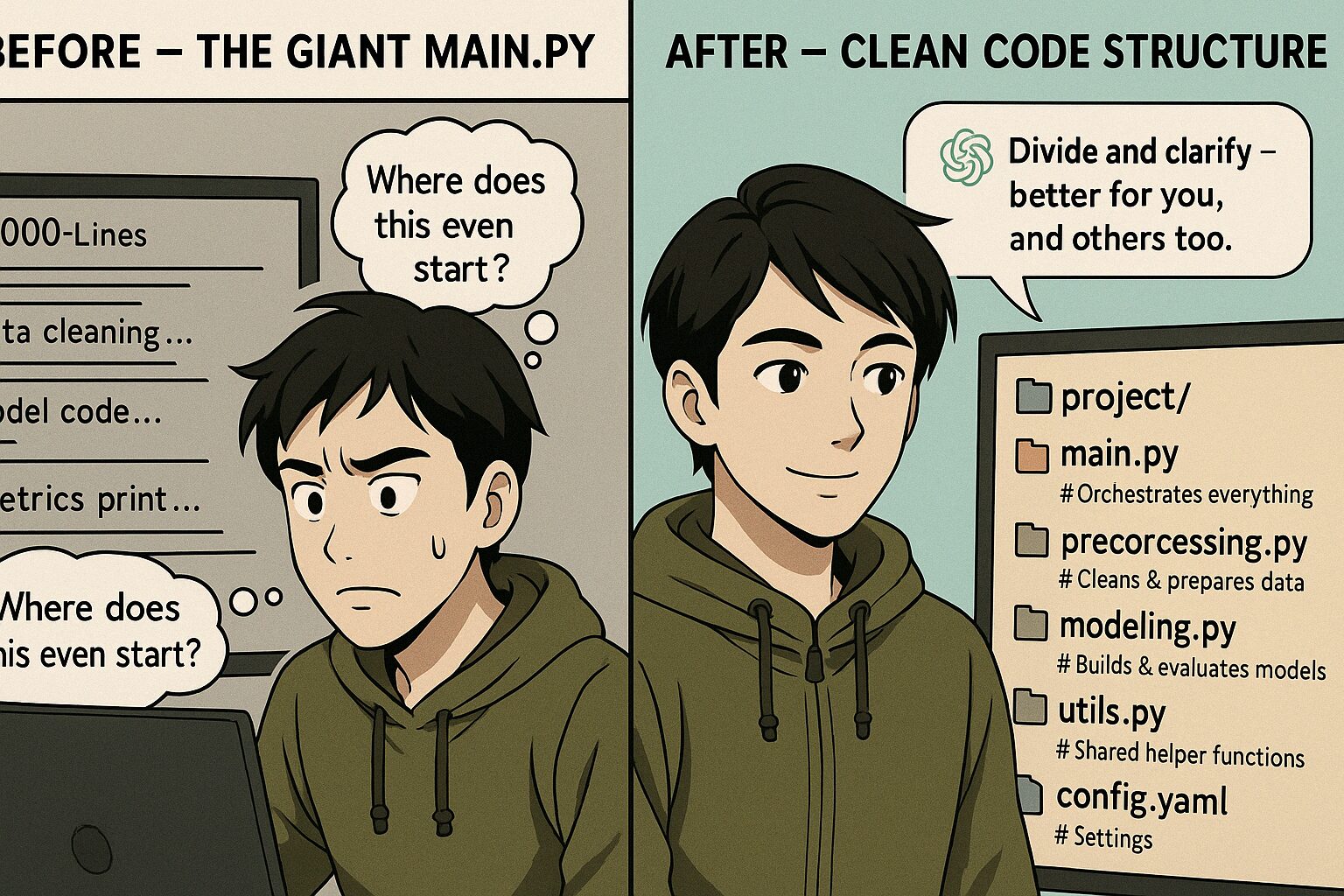
🪛 「なんかこのコード…育たないな」って思ったことありませんか?
製品開発の現場でPythonコードを書いていると、最初は動かすことに必死で、 全部1ファイルに詰め込んでた時期がありました。

──とりあえず動く。 でも、実験が進むにつれてバージョンが増え、 条件が増え、データが増え、 「どこを直せばいいか分からない」スパゲッティコードが出来上がっていく。
しかもそれを見せながらレビューに出ると──
「この前処理、他でも使うんだけど再利用できる?」
「モデルだけ変えたいとき、どうすればいい?」
「この評価の数値って、どのロジックで出したの?」
……正直、詰みました。
💥 コードは動いてる。けど、“他人にとって使いにくい”。
「main.pyが重い…」
「コピーして別スクリプトにしたけど、あとから差分が追えない…」
「関数化してなかったから、一部だけ実行ができない…」
そんな“地味だけど積もるストレス”に悩んでいたとき、 ChatGPTとのやりとりで提案されたのが、 **「責務ごとに.pyを分ける構成」**でした。

📌 この記事で得られること
この記事は、こんなPython開発の“もやもや”に心当たりがある方に向けて書いています:
- 気づけば1ファイルに全部詰め込んでて、後から見返すと「どこが何やってんの?」状態
- 前処理・モデル・評価が全部つながってて、分けたくてもどこから手を付けていいかわからない
- 別スクリプトでも同じ処理を使いたいけど、毎回コピペで再利用性ゼロ
- 「この処理だけもう一回試したい」が main.pyごと起動になっていて地味に面倒
──全部、かつての私です。
この記事では、そんな状態から脱却するために実践した**「処理の分割構成(preprocessing.py / modeling.py / evaluate.py / utils.py)」の考え方と実装例**を、リアルな開発現場での経験をもとに解説します。
さらに、ChatGPTと一緒に整理していく中で気づいた
**「main.pyは“司令塔”、他の.pyは“演奏パート”」**という設計思想にも触れながら、
可読性・再利用性・レビュー性を一気に上げる方法を紹介していきます。
🤖 もちろん、main.pyでのサンプルコードもお渡しします!
最後のほうに全部まとめて記載しておきます。
📂 main.pyも活用して全体の再現性・保守性を良くしたい方は👇

現場でたどり着いた「分けるだけで整う」ファイル構成
処理がごちゃっと1ファイルに詰まっていた頃、
「どこから読めばいいのか分からない」「前処理だけ再実行したいのに全部動いちゃう」
──そんな状況にモヤモヤしていたある日、私はChatGPTにこう問いかけました。
「処理が多すぎて、コードが読みにくくなってきました。どう整理すればいいですか?」
🤖 ChatGPT:
「責務ごとにファイルを分けると、再利用性・保守性・説明しやすさが一気に向上しますよ」
なるほど、責務ごとに分ける──たしかに、全部詰め込み型じゃなくて“役割ごと”に分けることで、構造も頭もすっきりする。
そこで、ChatGPTと壁打ちしながらたどり着いたのが、この構成です👇

絵にするとこんなイメージです👇
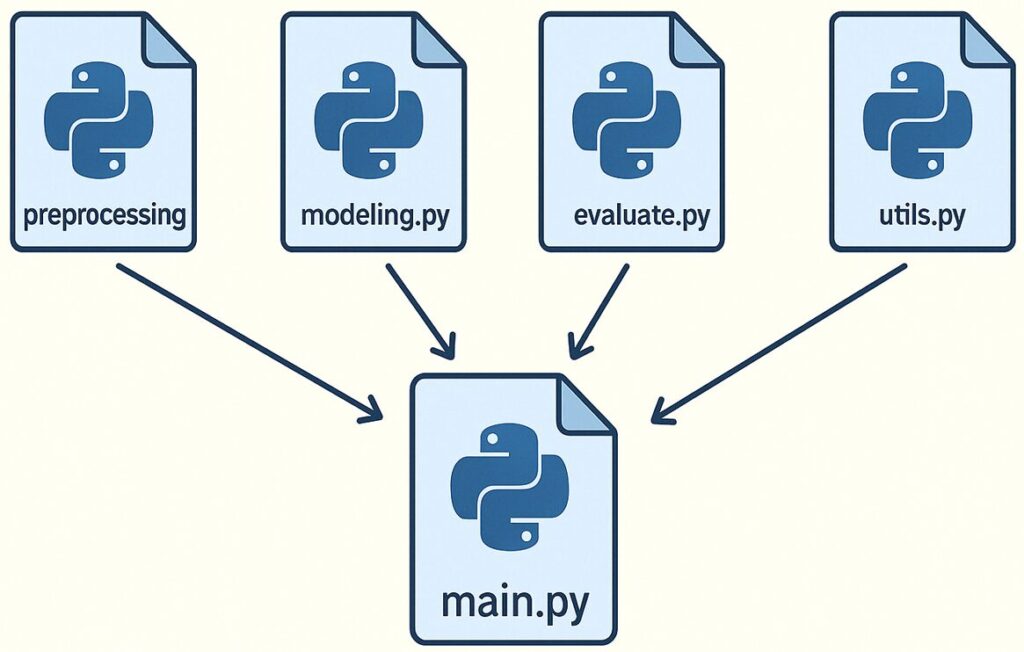
この構成にしてからは──
- 前処理だけ差し替えたいときに、preprocessing.pyだけ直せばOK
- 学習モデルの切り替えも、modeling.pyだけ見れば済む
- ロジックが分かれているから、エラー箇所の特定が爆速
- main.pyが“司令塔”として、全体の見通しが一目でわかる
ChatGPTのこの一言が特に刺さりました👇
「main.pyは“全体をつなぐ指揮者”、他の.pyは“演奏パート”です」
──この発想が、コードの構成を「ただ動かすもの」から「育てて使うもの」に変えてくれました。
preprocessing.py|データ読み込みと前処理は“まとめて外に出す”
ChatGPTに「構成は“役割ごとに分けましょう”」と言われて、
まず最初に切り出したのがこの preprocessing.py でした。
なぜか?
──前処理は地味だけど、どの案件でも毎回やる“最重要パート”だからです。
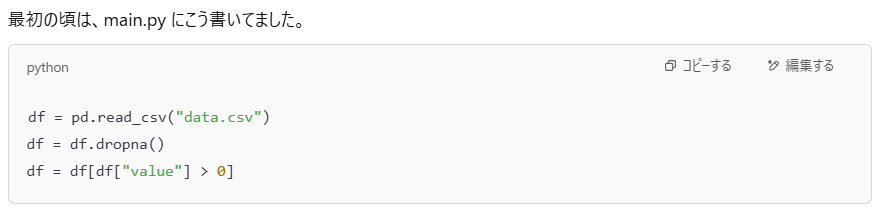
でも、これを全部 main に書くと、何度も同じ処理をコピペしたり、後で直したいときに「あれ?どの行だっけ?」となる。
レビュー時にも「前処理の中身ってどこ?」と聞かれる始末…。

💡 ここで得られたメリット
- main.pyが一気にスッキリして、読みやすくなった
- 前処理だけ再利用できるようになって、検証や別プロジェクトにも応用しやすくなった
- エラーやバグの調査範囲が明確になった(=前処理で止まったら、このファイルだけ見ればOK)
「データの読み込みと前処理、どう使い分ければいいですか?」
🤖 ChatGPT:
「load_data() は“ファイルの入口”、preprocess() は“現場に渡す前の整形”。目的を分けると構成が自然になります」
modeling.py|モデルの学習と保存は“ひとつの箱”にまとめよう
前処理を切り出してスッキリした私は、次に ChatGPT にこう聞きました。
「モデルの学習部分も整理したいんですが、どこまでをひとつにすべきですか?」
🤖 ChatGPT:
「学習と保存までをひとつの関数セットにしてまとめると、再利用性と構造の見通しが良くなりますよ」
──ということで、ChatGTPと一緒にmodeling.py を作成しました。
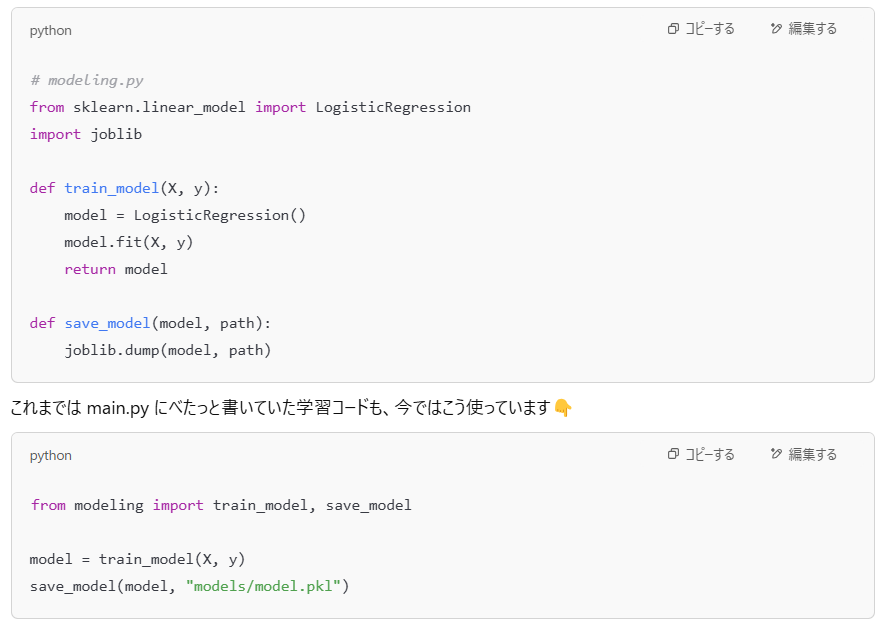
💡 ここがポイント
- モデルの種類を変えるときに、main.pyをいじらなくていい
→ train_model() の中だけ直せばOK - 保存処理もまとめてあるので、実行の流れが自然
→ 「学習したら保存する」の流れが main.py に明快に表れる - あとからのチューニングや実験の繰り返しが圧倒的にラク
→ 複数モデルのABテストにも応用しやすい
train_model() をパッケージのように扱うことで、main.py の中に「処理フローのストーリー」を書けるようになる。
そして学習ロジックの中身は modeling.py にお任せ。
この構成にしてから、説明もレビューも爆速になりました。
evaluate.py|評価は“あとから何度でも”できるようにしておく
モデルができたら、次にやるのは「ちゃんと使えるか?」の確認。
でも、評価指標の計算って──
実はあとから何度も見直したくなるものなんです。
私も最初は、学習コードの下に直接こう書いていました👇
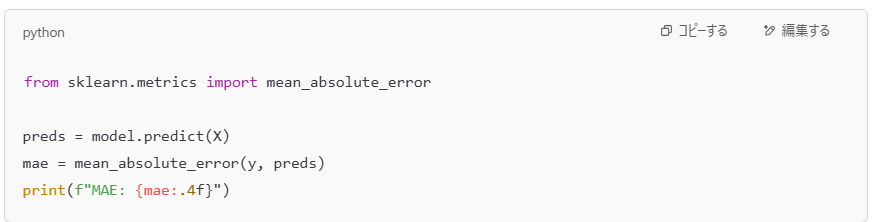
でも、パラメータを変えるたびに同じ処理をコピペしては実行…
あとから「他の指標も見たい」となって書き足して…
main.pyが地味にぐちゃってくる。
そこで、ChatGPTにこう聞きました。
「評価だけ何度も試したいんですけど、これも分けたほうがいいですか?」
🤖 ChatGPT:
「評価処理は関数化&ファイル分離しておくと、再実行しやすく、mainもスリムになります」
というわけで evaluate.py を作りました👇
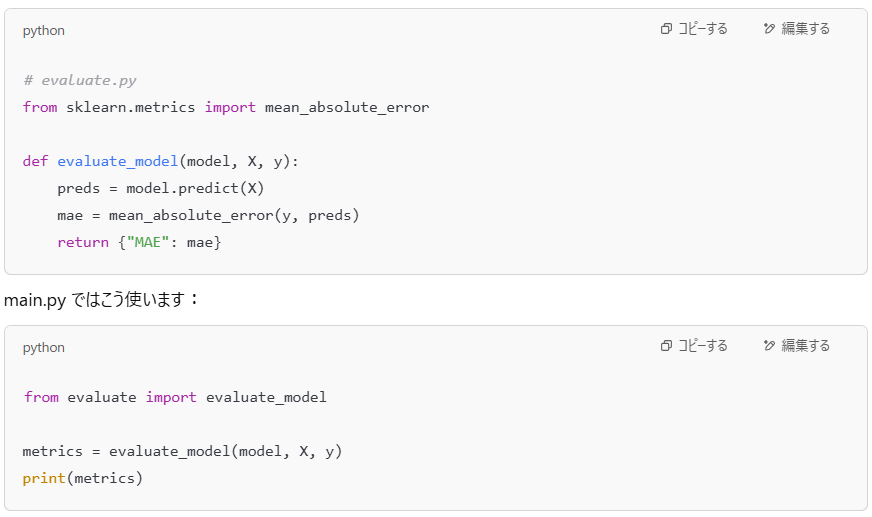
💡 この構成のいいところ
- main.py の末尾に「評価」ってひと目でわかる
- あとから指標を追加・変更しやすい(F1やR²などもサクッと追加可能)
- 評価処理だけ別データで再実行できる(=実験パターンが増えても柔軟)
ChatGPTの言葉を借りると──
「評価は“何がよかったか”を説明するための材料。だからこそ、独立させておく価値があります」
このアドバイスも、地味に沁みました。
評価だけを“独立パート”にしておくと、main.py にも余計なロジックが混ざらないし、
レビュー時にも「あ、この関数で評価したんですね」と一発で伝わる。
utils.py|“よく使うやつ”は道具箱にまとめとけ
開発を進めていると、だんだんこういう関数が増えてきませんか?
- 出力フォルダがなければ作るやつ
- ファイル名をいい感じに生成するやつ
- 複数のパスを結合するやつ
…いわば「道具として何度も使うやつ」です。
私も最初は、そういう処理を毎回 .py の先頭や末尾にベタ書きしてました。

──気づけば同じコードが、3箇所のスクリプトに散らばってる。
「「この ‘os.makedirs’、いろんなファイルに書いてるんですが、まとめた方がいいですか?」
🤖 ChatGPT:
「そのような汎用処理は ‘utils.py’ に集約すると、再利用性が高まり保守も楽になります」
たしかに、**「どこでも使うもの=ひとつにまとめる」**は鉄則。
というわけで、私は utils.py という“道具箱”を用意しました👇
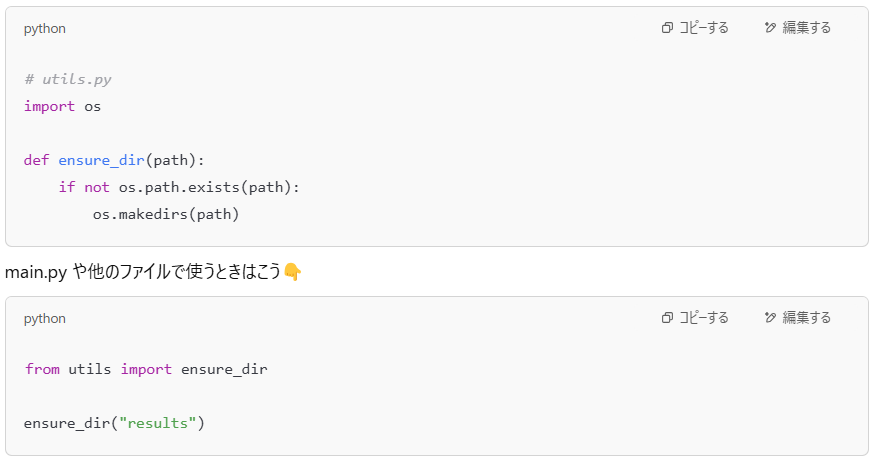
💡 これが意外と便利だった理由
- 複数のスクリプトで同じ機能を使い回せる
- 1箇所にあるから修正も1回で済む
- ファイル構成を見たときに「雑用はここ」ってわかる
ChatGPTいわく:
「“utils”は目立たないけど、プロジェクト全体の“骨組み”になります」
──ほんとその通りでした。
あとから「フォルダ構成を変えたい」「ファイルの命名ルールを調整したい」ってなっても、
utilsだけ触れば全部に反映されるので、保守コストが爆下がりします。
📂 そもそも可読性を上げる意味とは?を知りたい方はこちらへ👇

まとめ|“処理を分ける”だけで、コードは見違える
正直、最初の頃の私は「全部まとめて1ファイルで書けば早くね?」と思ってました。
でも実際には──
- どこに何があるかわからない
- 同じ処理を何度も書いてしまう
- バグ修正や追加実装のとき、手がつけられなくなる
という“地味なストレス”が蓄積されていったんです。
そこに、ChatGPTとのやり取りを通じて学んだ考え方が刺さりました👇
「main.pyは司令塔。他の.pyは役割ごとの演奏パート」
この発想でコードを分けてみたら、 **main.py は“読むだけで処理の全体像がわかる”**し、
**それぞれの.pyは“必要なときにだけ開けばいい”**ようになったんです。
✅ ここまで分けた私の構成(再掲)
この構成にしてからは、明らかにこう変わりました:
- 「ここだけ実行したい」がすぐできる
- 「どこに何があるか」の説明が一瞬で済む
- 「あとでまた使いたい」がスムーズになる
そしてなにより──
コードを自分の手で“育ててる”感覚が生まれたんです。

🧾 load_data.py(※前処理と別に読み込み処理を切り出す場合)
import pandas as pd
def load_data(path):
return pd.read_csv(path)🧼 preprocessing.py
def preprocess(df):
df = df.dropna()
df = df[df["value"] >= 0] # 負の値を除去
X = df.drop("target", axis=1)
y = df["target"]
return df, X, y🤖 modeling.py
from sklearn.linear_model import LogisticRegression
import joblib
def train_model(X, y):
model = LogisticRegression()
model.fit(X, y)
return model
def save_model(model, path):
joblib.dump(model, path)📊 evaluate.py
from sklearn.metrics import mean_absolute_error
def evaluate_model(model, X, y):
preds = model.predict(X)
mae = mean_absolute_error(y, preds)
return {"MAE": mae}🛠 utils.py
import os
def ensure_dir(path):
if not os.path.exists(path):
os.makedirs(path)🚀 main.py
import logging
from datetime import datetime
from load_data import load_data # または preprocessing.py に含まれる場合は不要
from preprocessing import preprocess
from modeling import train_model, save_model
from evaluate import evaluate_model
from utils import ensure_dir
# ログ設定
logging.basicConfig(
filename='output.log',
level=logging.INFO,
format='%(asctime)s [%(levelname)s] %(message)s'
)
def main():
logging.info("処理を開始します")
logging.info(f"開始時刻: {datetime.now()}")
# データ読み込み
try:
df = load_data("data/input.csv")
logging.info("データの読み込みが完了しました")
except Exception as e:
logging.error(f"データの読み込みに失敗しました: {e}")
return
# 前処理
df_processed, X, y = preprocess(df)
logging.info("前処理が完了しました")
# モデル学習
model = train_model(X, y)
logging.info("モデルの学習が完了しました")
# モデル保存
save_model(model, "models/model.pkl")
logging.info("モデルの保存が完了しました")
# 評価
metrics = evaluate_model(model, X, y)
logging.info(f"評価結果: {metrics}")
logging.info("処理が正常に終了しました")
if __name__ == "__main__":
main()📣 最後にひとこと:
誰かに渡すコードじゃなくても、
「未来の自分に渡すコード」だと思って、分けておくのがおすすめです。
ChatGPTとの壁打ちで気づいたことはたくさんありますが、
“構造を整える”だけで、開発はこんなにラクになるんだということが、一番大きな発見でした。
次回も”現場でのリアルな体験”を基に、記事を書いていきたいと思います!


コメント